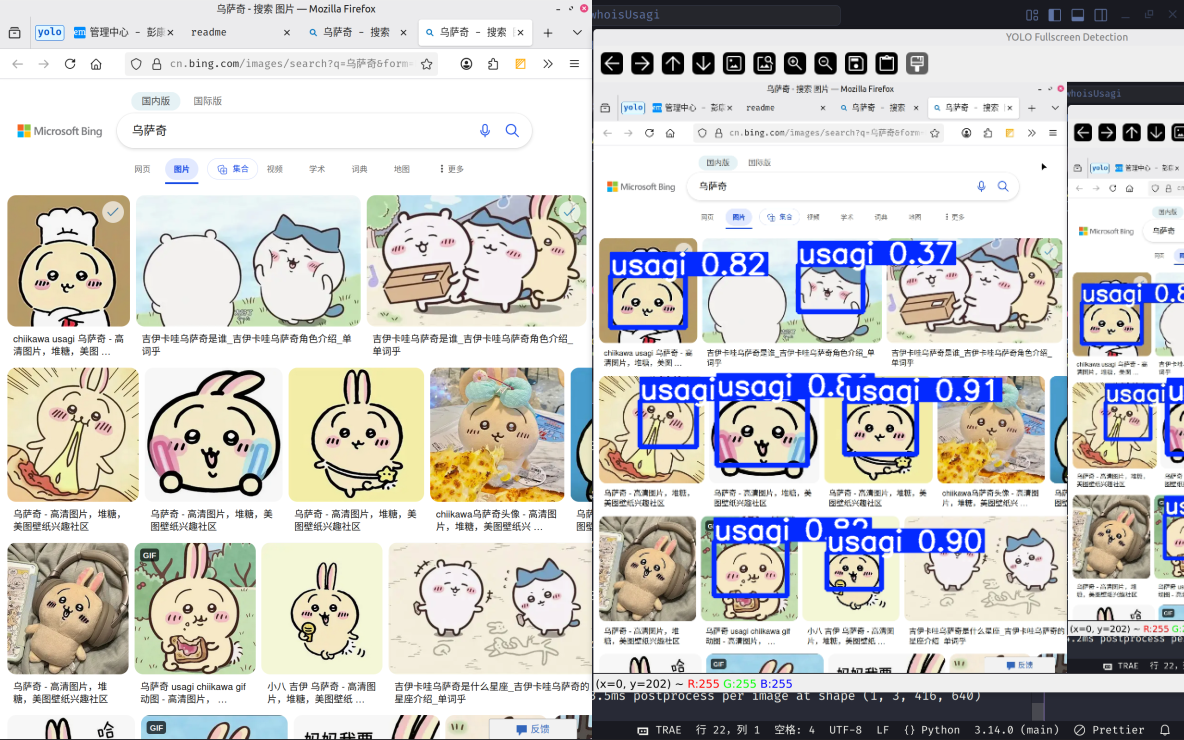

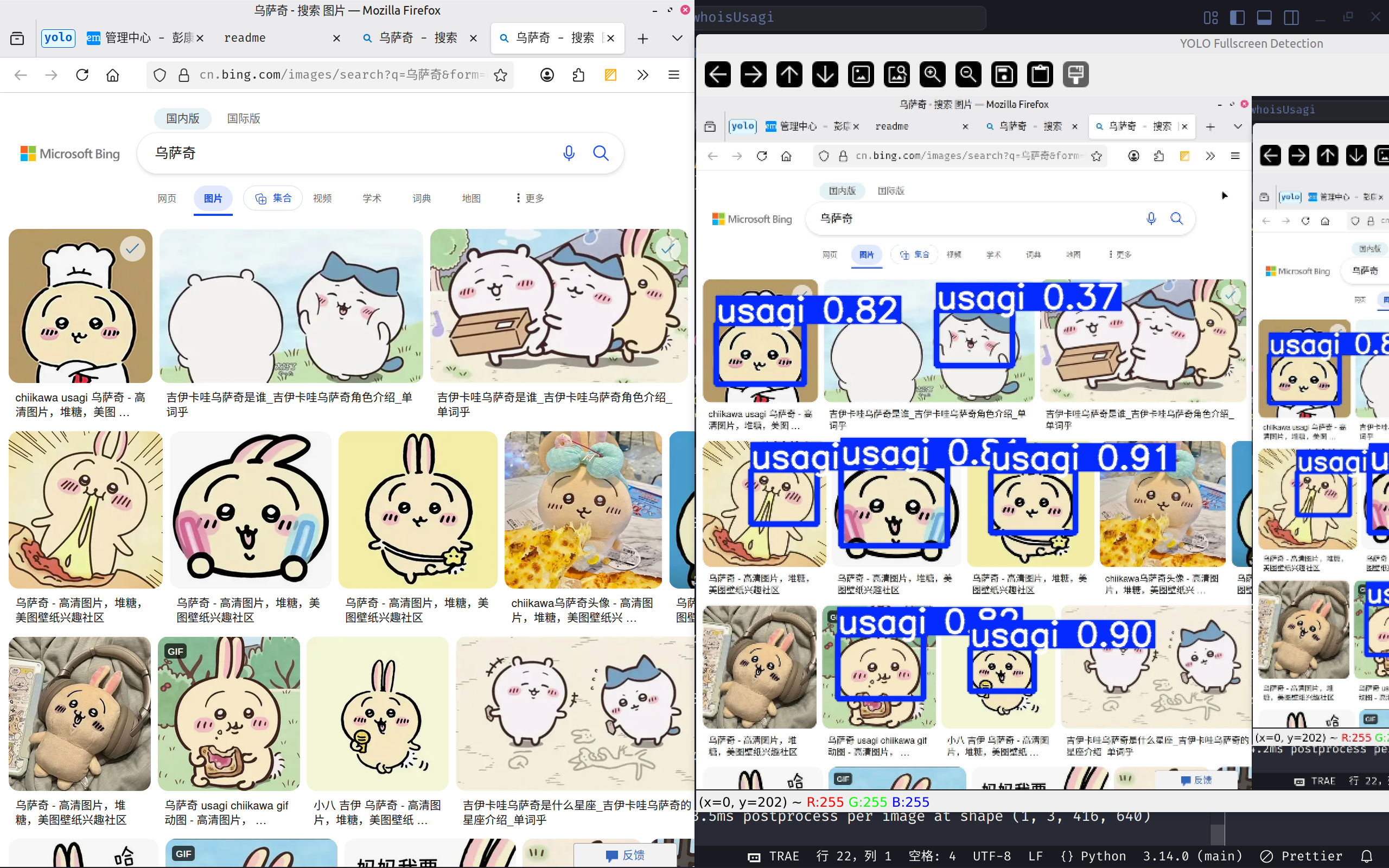
效果
我的电脑配置
我在我的电脑上训练本文的模型,使用0.86小时,这里给出电脑配置作为参考。
Linux Mint 22.2 x86_64
i9-13900HX
内存 32G
5070ti laptop 100W 12G
环境配置
因为我把环境弄坏了,所以才有了这一节
首先需要安装Anaconda,Anaconda是一个开源的Python和R编程语言的发行版,用于科学计算(数据科学、机器学习、大数据处理和预测分析)。它包含了conda、Python等180多个科学包及其依赖项。
与Anaconda相比,Miniconda是一个更小的发行版,它只包含conda和Python及其必要的依赖项,不包含预装的科学包。如果需要更轻量级的安装或希望自定义安装的包,可以选择Miniconda。
如果你没看懂以上2段,那么按照教程直接安装即可。
然后创建一个新的虚拟环境,取一个你喜欢的名字,比如usagi并激活它
conda create -n usagi python=3.12
conda activate usagi
接下来需要安装一些必要的包。安装ultralytics,就会自动安装它的依赖,包括pytorch等。
pip install ultralytics
安装labelImg
pip install labelImg
这里如果下载速度过慢,你可以考虑使用国内的镜像源,比如清华大学的镜像源。
有人能看看西交的镜像源吗?
新建一个train.py文件,内容如下
from ultralytics import YOLO
model = YOLO("yolo12x.pt")
这里需要你根据电脑配置把yolo12x.pt替换为其他的模型,比如yolov12n.pt等。最后的字母表示模型的大小,越大对配置要求越高,n表示小,l表示大。我使用了最大的x。
然后运行train.py文件
python3 train.py
如果你激活了正确的conda环境,那么接下来会从github下载预训练模型,请保证你的网络环境正常。
等下载完成后,模型会被保存在当前目录下的yolo12x.pt文件中。
再试试labelImg是否安装成功
labelImg
如果成功,会弹出一个窗口。
这时,环境就配置完成了。
准备数据
在训练开始之前,我们需要准备好数据集。请按照以下结构新建文件夹:
dataset
├── all
├── images
│ ├── train
│ └── val
└── labels
├── train
└── val
dataset和all文件夹可以换成你喜欢的名字。我上网搜索了一些乌萨奇的图片,把它们放到了dataset/all文件夹下。
我们会使用训练集来训练模型。训练完成后,我们会使用验证集来评估模型的性能,接下来可能会根据模型在验证集上的表现,修改参数,然后重新训练。一般训练集的数量要大于验证集的数量。我使用了82张图片作为训练集,17张图片作为验证集。按照你的想法,把部分图片放到dataset/images/train,另一部分放到dataset/images/val
YOLO标签文本文件采用一行表示一个目标的格式,内容为空格分隔的五个数值:第一个是类别ID,后四个分别是归一化的中心点x坐标、中心点y坐标、目标宽度和目标高度。
例如图片dataset/images/train/4ESjegOESo2P6v5.jpg
yolo会自动把images替换为labels来找到这个文件dataset/labels/train/4ESjegOESo2P6v5.txt
这个文件的内容是
0 0.379883 0.560547 0.724609 0.574219
显然我们不可能手动计算这些值,我们需要使用一些工具来标注图片。这里使用labelImg工具来标注图片。
打开labelImg工具
点击 打开目录 ,选择dataset/images/train文件夹。点击改变存放目录,选择dataset/labels/train文件夹。
按下w,然后长按左键拖动创建一个矩形框,框住乌萨奇。
然后,你的labelImg窗口就会闪退。因此,下一篇文章将不会使用labelImg。
观察终端的报错信息,ctrl+左键打开报错的文件,给所有应该为int类型的参数,都添加一个int()函数。以后还会遇到相同的问题,只需要打开对应文件并修改即可。
p.drawLine(self.prev_point.x(), 0, self.prev_point.x(), self.pixmap.height())
# 修改后
p.drawLine(int(self.prev_point.x()), 0, int(self.prev_point.x()), int(self.pixmap.height()))
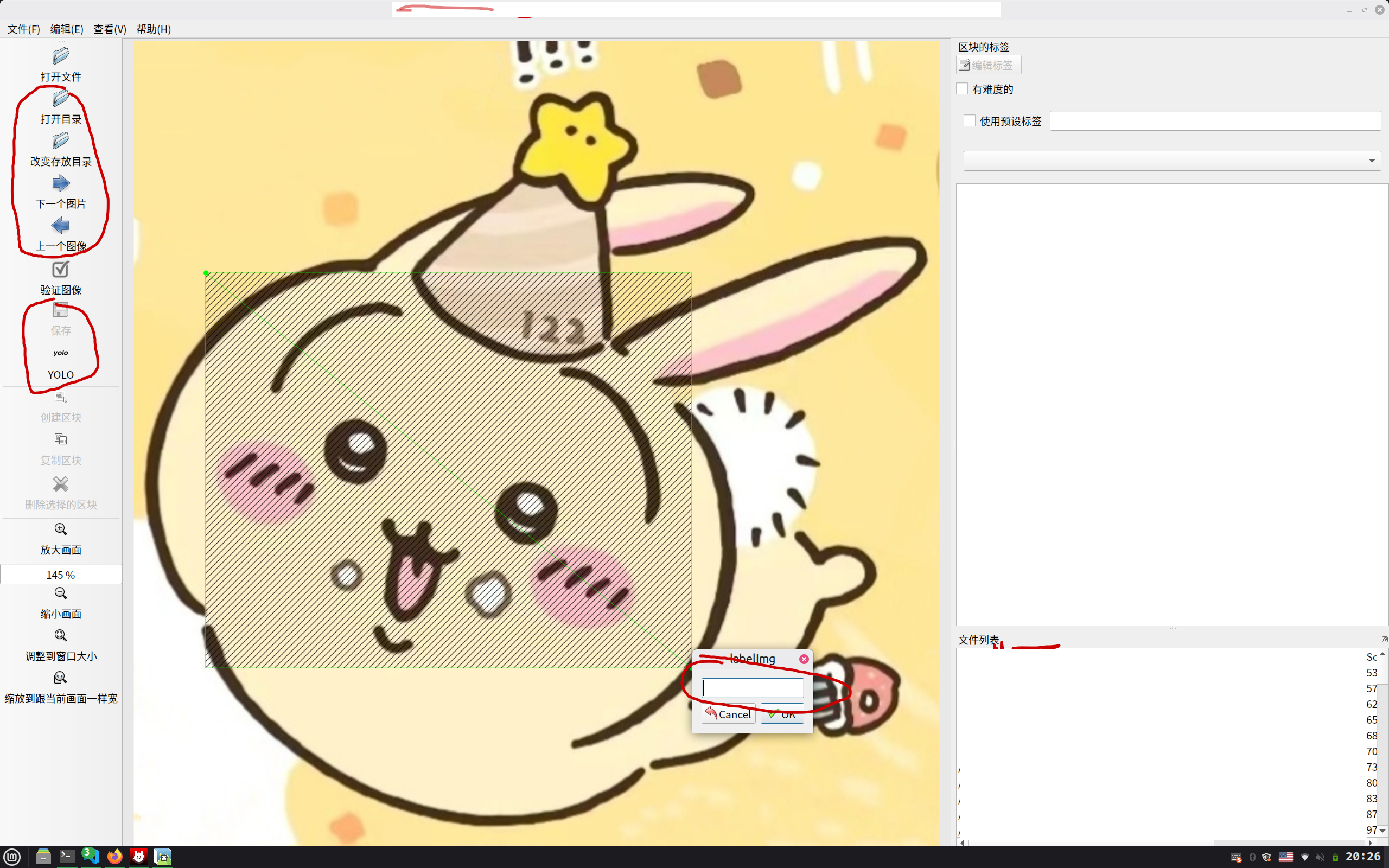
红圈是你需要注意的地方。部分区域被打码了,可能看着很奇怪。
框选之后,会要求你输入label,这里输入0即可,因为这个项目只有一个类别,就是乌萨奇。
标注完一张图片的所有乌萨奇后,按下 ctrl+s 键保存标注。接下来,按下d键,切换到下一张图片,重复这样的劳动,直到所有图片都被标注完毕。
接着,我们需要把验证集的图片也标注好,方法同上。
这一切都完成后,新建一个usagi.yaml文件,内容如下
path: dataset
train: images/train
val: images/val
names:
0: usagi
这里 0 后面的usagi表示类别名称,你可以根据自己的喜好修改。
训练模型
迁移学习是指将一个已经训练好的模型的知识迁移到另一个相关任务上。
在这里,我们使用了预训练模型yolo12x.pt,它已经使用了大量数据进行训练,使得我们只需要较少的图片,就可以训练出一个效果不错的模型。
打开train.py文件,修改如下
from ultralytics import YOLO # type: ignore
model = YOLO("yolo12x.pt")
res = model.train(
data="./usagi.yaml", batch=4, epochs=500, device=0, save=True, resume=False
)
逐个介绍参数:
data:数据集的配置文件路径,这里是上文创建的usagi.yaml。batch:每个批次的样本数量。越大,训练速度越快,但是显存占用也会增加。epochs:训练的轮数,这里是500。越大,训练时间越长,但是模型的性能可能会更好。device:训练使用的设备,这里是0,表示使用第一个也是我唯一的GPU。save:是否保存训练过程中的模型。resume:是否从上次中断的地方继续训练,这里是False。
模型在训练时,将会把相关数据保存到runs/detect/train<num>文件夹下。这里的<num>是一个数字,每次训练都会自动增加。请你记住这个数字。
训练过程中,你可能会因为显存不足而中断,这时需要把batch减小。同时你可以考虑开启resume,下次训练中断后,修改这一行,加载上次中断的模型。
model = YOLO("yolo12x.pt")
# 修改后
model = YOLO("runs/detect/train1/weights/last.pt")
在训练结束后,你可以在终端上看到模型的性能,我们先只看精度metrics/precision(B),如果这个数字太小,说明模型的性能不是很好,你可以考虑修改参数,然后重新训练。
使用模型
本地图片
我们使用openCV加载图片,并用模型对图片进行推理。
# detect.py
from datetime import datetime
import cv2
from ultralytics import YOLO # type: ignore
model = YOLO("./runs/detect/train18/weights/best.pt") # 修改为你的模型路径
res = model("img/Image_1760844699649.jpg")
res_img = res[0].plot()
date_str = datetime.now().strftime("%Y%m%d-%H-%M-%S")
cv2.imwrite(f"./img/res-{date_str}.png", res_img)


屏幕
由于这一特性不太有用,并且和操作系统相关,因此这里只展示效果。
img
摄像头
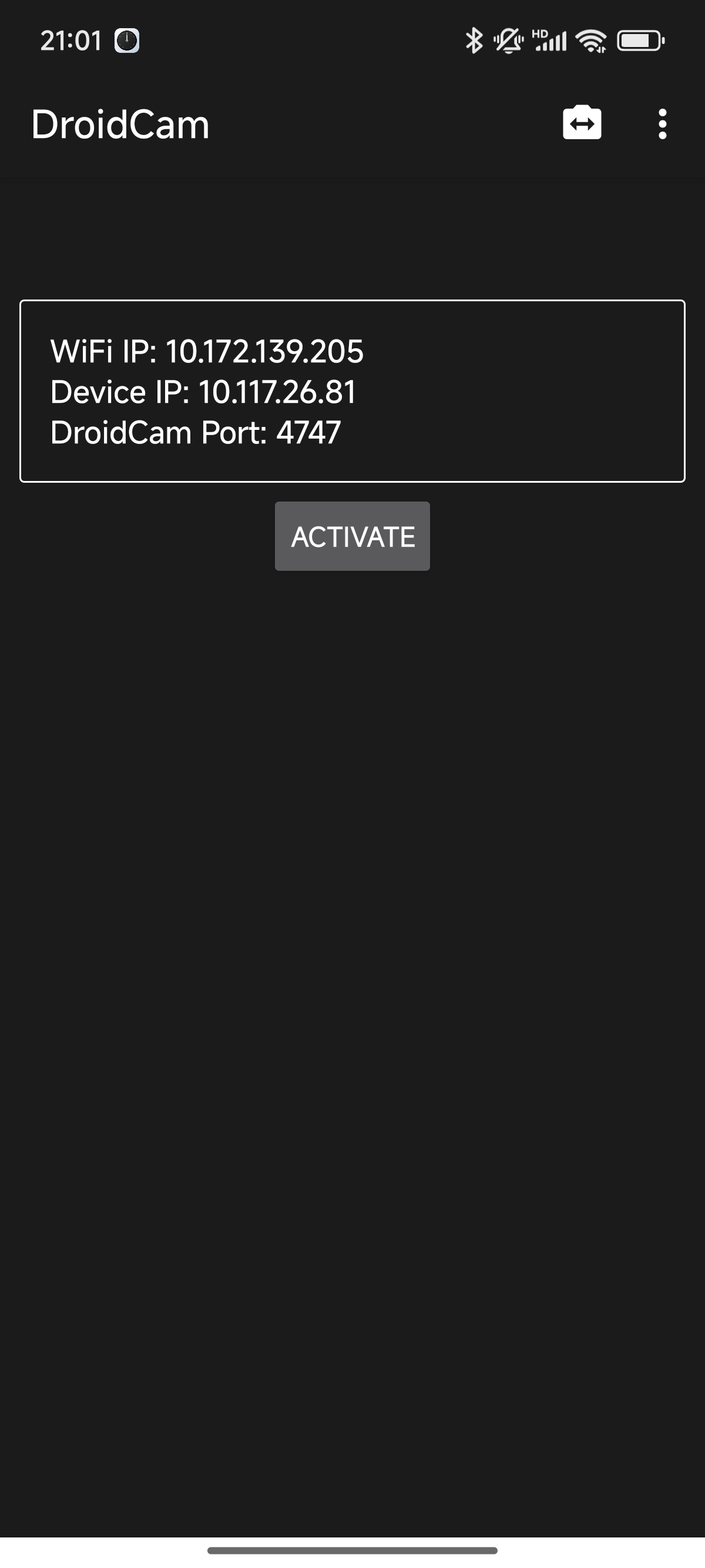
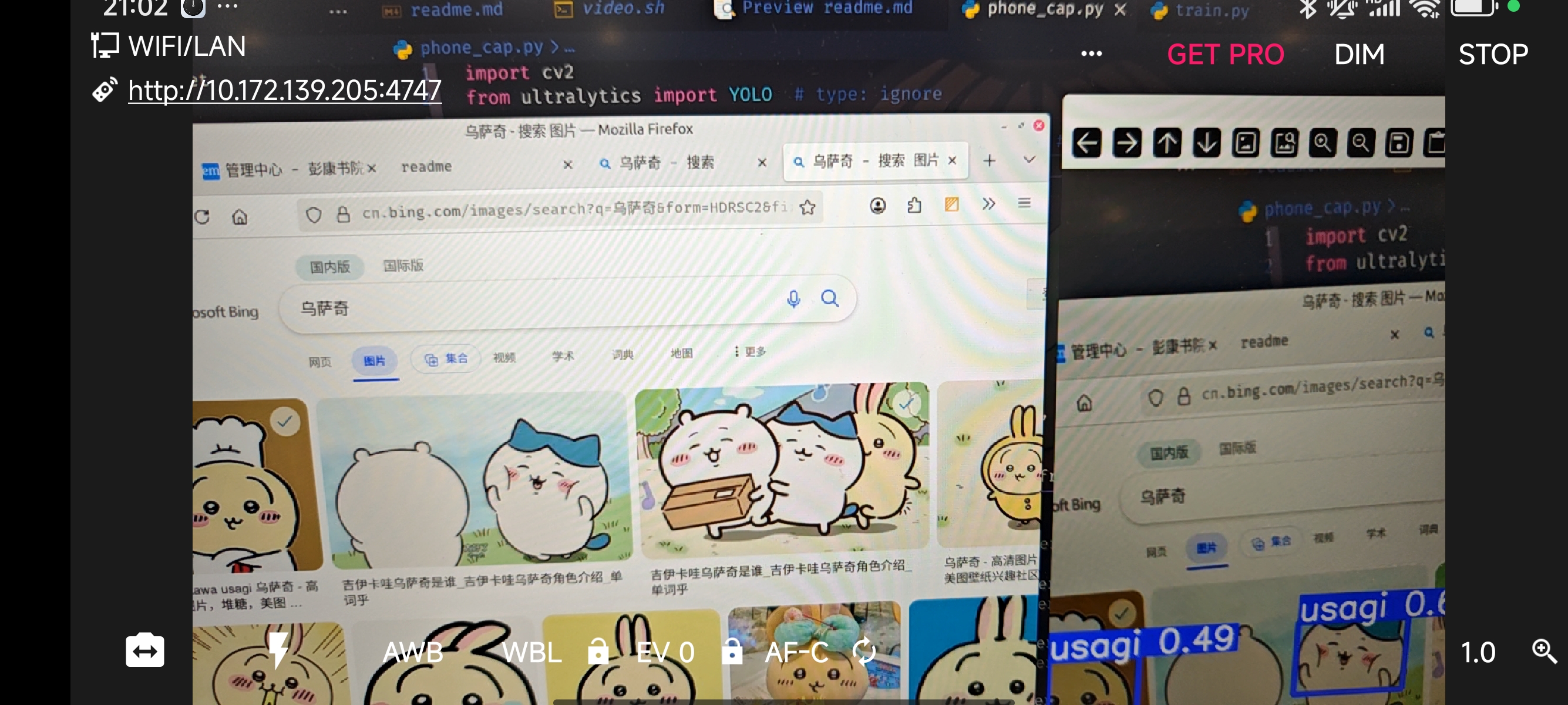
这里使用手机摄像头,进行推理。
在我的安卓手机上安装了DroidCam,它可以把手机的摄像头作为视频流输出。
# phone_cap.py
import cv2
from ultralytics import YOLO # type: ignore
model = YOLO("./runs/detect/train18/weights/best.pt") # 修改为你的模型路径
stream_url = "http://192.168.5.41:4747/video" # 修改为你的视频流地址
cap = cv2.VideoCapture(stream_url)
scale = 0.4
while True:
ret, frame = cap.read()
if not ret:
print("not ret")
break
frame_small = cv2.resize(frame, (int(2560 * scale), int(1600 * scale)))
results = model(frame_small)
annotated_frame = results[0].plot()
cv2.imshow("YOLO Fullscreen Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
cv2.destroyAllWindows()



















这一切,似未曾拥有